
기업 AX에서 DeepSeek V4가 갖는 의미
DeepSeek V4는 '1황'이 아니라 '단가 배율'로 기업에 질문을 던진다. 온프레미스·데이터 주권, 그리고 AXyBench 한국 실무 측정으로 본 진짜 위치.

- AXyNow
- DeepSeek
- 기업AX
- 온프레미스
- AXyBench
프리미엄 AI 매거진 AXyNow, 손상윤입니다.
기업이 AI를 도입할 때 진짜 질문은 "어느 모델이 1황이냐"가 아닙니다. "같은 일을, 수십 배 싼값에 시키면 안 되나?"입니다. 벤치마크 1~5점 차이는 손익계산서에 닿지 않지만, 단가 배율은 첫 줄에서부터 체감되기 때문이죠. DeepSeek V4는 정확히 이 질문을 겨냥하고 나왔습니다.
1년 만의 등장, Deepseek V4
DeepSeek가 4월 23일 V4를 프리뷰로 열었습니다. V3 발표 후 무려 1년 만이죠. 늦어진 이유는 여러 가지지만, 정말 중요한 한 가지는 화웨이 칩에서 추론되도록 최적화했다는 점입니다.
이건 단순한 기술 디테일이 아닙니다. 엔비디아 없이도 자국 칩으로 돌아가는 모델이라는 건, 추론 인프라를 외부(미국 칩)에 의존하지 않겠다는 신호예요. 그리고 이 "의존하지 않는다"는 서사가, 뒤에서 다룰 기업의 온프레미스·데이터 주권 이야기와 그대로 이어집니다.
MoE, 기업 AX의 희망
V4는 MoE(Mixture of Experts) 아키텍처입니다. V4 Pro는 1.6조 파라미터에 활성 49B, V4 Flash는 284B에 활성 13B. 둘 다 1M 컨텍스트가 기본입니다.
MoE는 전체를 다 켜는 Dense와 달리, 입력마다 일부 전문가만 활성화합니다. 그런데 MoE에도 약점이 있어요. KV 캐시 효율이 낮아서, VRAM이 넉넉한 환경에서 다양한 요청을 배치로 묶어 서빙할 땐 Dense보다 불리합니다.
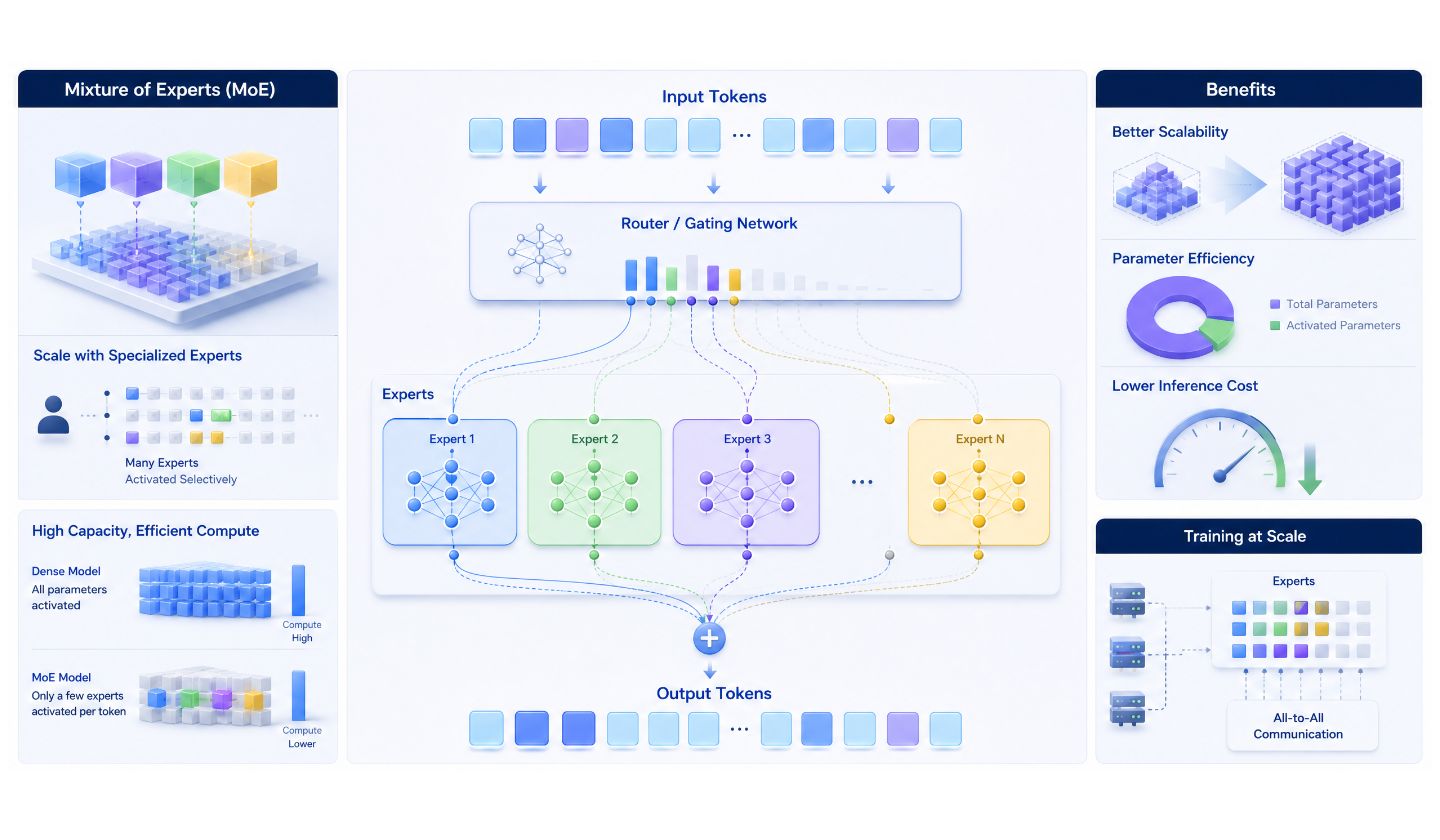
여기서 반전이 있습니다. 기업 AX 환경은 입력 쿼리가 제한적입니다. 사내 문서, 정해진 양식, 반복되는 업무 — 요청의 다양성이 낮고 패턴이 일정하죠. 즉 MoE의 약점인 "다양한 배치"가 애초에 잘 안 생기는 환경입니다. 그러니 MoE의 약점은 상쇄되고, 활성 파라미터만 켜서 전력효율적으로 추론한다는 MoE 본연의 장점만 남습니다. 특히 V4 Flash는 활성 13B 경량이라, VRAM에 일단 올려두기만 하면 추론 효율이 극강입니다.
가격 대비 성능 Global 1위
DeepSeek V4 Pro를 두고 "성능은 SOTA 근접, 가성비는 SOTA"라고 말합니다. 핵심은 가격이에요. 5월 31일 75% 할인 프로모션이 끝나는데, 돌연 프로모션 이후에도 이 가격을 유지하겠다고 했습니다. 인하가 아니라 할인가를 정상가로 굳히는 조정이죠.
SOTA 모델들과 나란히 놓으면 차이가 한눈에 들어옵니다. (출력 1M 토큰 단가 기준)
| 모델 | 입력 $/1M | 출력 $/1M | V4 Flash 대비 출력 배율 |
|---|---|---|---|
| GPT-5.5 | 5.00 | 30.00 | 107배 |
| Claude Opus 4.7 | 5.00 | 25.00 | 89배 |
| Claude Sonnet 4.6 | 3.00 | 15.00 | 54배 |
| Gemini 3.1 Pro | 2.00 | 12.00 | 43배 |
| DeepSeek V4 Pro | 0.435 | 0.87 | 3.1배 |
| DeepSeek V4 Flash | 0.14 | 0.28 | — |
출처: DeepSeek 공식가 직결, 조회 2026-05-27. V4 Pro는 75% 인하를 영구 적용(프로모션 아님), 캐시 적중 시 입력가 추가 인하.
같은 1M 토큰을 뽑는 데 GPT-5.5는 30달러, V4 Flash는 28센트. 107배입니다. V4 Pro조차 SOTA의 약 1/30 수준이고요. 이게 "벤치 점수보다 단가 배율이 손익에 먼저 닿는다"는 말의 실체입니다.
기업은 결국 오픈웨이트를 필요로 합니다
외부 API를 쓰는 게 가장 손쉬운 도입 시나리오지만, 규모가 큰 기업일수록 보안 때문에 온프레미스를 원하게 됩니다. 그래서 자체 추론 환경에 올릴 수 있는 오픈웨이트 모델을 찾게 되죠.
DeepSeek V4는 정확히 이 지점을 노립니다. 앞서 화웨이 칩 최적화를 신호라고 한 이유가 여기예요 — 외부 인프라에 의존하지 않는 모델이라는 점이 그대로 이어집니다. 중국 서버에서 추론되는 게 불안하다면, 그냥 이 모델을 폐쇄된 내부망에 직접 올리면 모든 게 해결됩니다. 특히 V4 Flash는 활성 13B라, VRAM만 확보하면 자체 추론 효율이 매우 훌륭하고요.
아무리 Anthropic·OpenAI가 고객 데이터를 학습하지 않는다고 해도, 기업으로서의 데이터 주권 앞에서는 심리적으로 불안할 수밖에 없습니다. SOTA급 성능을 쓰려면 철저하게 그들의 추론 서버에 의존해야 한다는 점은, 그래서 아쉬운 대목입니다.
업무 신뢰도: 싸다고 다가 아니다
물론 싸다고 다가 아닙니다. 신뢰할 만한지, 지능은 어떤지, 그리고 한국 비즈니스 환경에서의 성능이 중요하죠.
흥미로운 건 DeepSeek가 B2B에서 급부상 중인 Claude의 강점, Native Interleaved Reasoning을 거의 그대로 차용했다는 점입니다. 이건 추측이 아니에요 — DeepSeek의 API docs에는 대놓고 "Anthropic API" 호환 방식이 명시돼 있고, 현존 provider 중 interleaved reasoning을 같은 방식으로 구현한 건 Anthropic과 DeepSeek 둘뿐입니다. 사고 과정을 사용자의 네이티브 언어로 진행한다는 점까지 동일하고요.
혼잣말하며 스스로 사고를 검증하고 교정하는 패턴을 보면, DeepSeek가 처음 등장했을 때와 Claude Opus가 코딩 1황으로 올라섰을 때의 사고 과정이 겹쳐 보입니다. 기업 AX에서 가장 중요한 tool calling에서도 정확도와 수행률이 매력적입니다.
AXyBench: 한국 실무로 직접 재보면
그럼 한국 비즈니스 실무에서는 몇 점일까요. AXyNow가 직접 측정하는 AXyBench로 재봤습니다.
읽는 법. AXyBench 점수는 모델의 "절대 지능"이 아니라 한국 비즈니스 실무 + 고난도 변별이라는 렌즈에서의 순위입니다. 일부러 어려운 문항·함정을 깔아 변별을 만들고, 한국 도메인(세무 등)을 무겁게 가중합니다. 그래서 DeepSeek의 글로벌 코딩·수학 명성과 이 점수는 다른 것을 잽니다.
| 모델 | 한국 세무 | 코드 | 문서 | 평균 |
|---|---|---|---|---|
| Claude Opus 4.7 | 86.8 | 95.2 | 94.0 | 92.0 |
| Gemini 3.1 Pro | 92.6 | 87.2 | 90.8 | 90.2 |
| GPT-5.5 | 94.8 | 88.4 | 86.8 | 90.0 |
| DeepSeek V4 Pro | 72.4 | 80.8 | 73.0 | 75.4 |
| DeepSeek V4 Flash | 70.4 | 83.8 | 71.4 | 75.2 |
세 가지가 눈에 띕니다.
첫째, Flash가 Pro와 사실상 동률(75.2 vs 75.4)입니다. 가격은 1/3인데 점수는 같아요. "Flash가 Pro 대비 성능 차이가 작으면서도 훌륭하다"는 게 수치로 확정됩니다.
둘째, 코드에서 Flash는 83.8로 Pro마저 추월하고 SOTA 팩(GPT 88·Gemini 87) 코앞까지 갑니다. 분류·요약·1차 초안·대량 추출 같은 비용 민감 반복 업무라면, V4 Flash로도 충분히 AXy합니다.
셋째, 무너지는 곳도 분명합니다. 까다로운 고난도 문항에선 DeepSeek가 한국 세무(복식부기 의무 판정·가산세 감면율)와 차트 설계의 반(反)아부 같은 데서 일관되게 헛디딥니다. 되는 문제는 SOTA급, 안 되는 고난도는 뚝 떨어지는 변동성이죠.
그리고 한 가지 — DeepSeek는 V4 Pro를 "SOTA 근접"이라 말하지만, AXyNow가 한국 실무로 직접 재면 Pro조차 SOTA(90~92)에 한 티어 못 미치는 75점대입니다. 재차 확인해도 격차는 그대로입니다. 글로벌 일반 벤치의 "근접"과, 한국 세무·문서 실무에서의 현실은 다릅니다. 우리가 가진 이 렌즈가, 마케팅 문구와 현실의 간극을 보여주는 자리입니다.
점수만큼 중요한 건 단발 신뢰도
그런데 반복해서 써보면 알게 되는 게 하나 더 있습니다. 점수가 같아도, 그게 "매번 흔들려서"인지 "매번 똑같이 틀려서"인지는 전혀 다른 얘기라는 겁니다. 기업이 진짜 묻는 건 "한 번 받은 답을 그냥 믿어도 되나, 아니면 여러 번 돌려 검수해야 하나"니까요. AXyNow는 이 단발 신뢰도를 점수와 별도로 평가에 남기기로 했습니다.
- Flash·세무: 안분 계산 같은 반복 골격은 안정적입니다. 그런데 복식부기 의무·수정신고 감면율 같은 고난도 판정은 호출마다 답이 갈립니다. → 변동형. 한 번 잘 나온 답을 그대로 믿기보다 재실행·교차검증.
- Flash·문서: 내용 골격은 안정적인데, 간혹 답변 전체가 중국어로 새는 경우가 있습니다. 드물지만 단발 운영에선 치명적인 사고죠. → 언어 일관성 리스크. 중요 문서는 출력 언어 확인.
- Pro·세무·문서: Flash보다 호출 간 편차가 작습니다. 다만 감면율이나 거짓 전제 교정처럼 매번 똑같이 약한 항목이 있는데, 이건 운이 아니라 일관된 한계입니다.
정리하면 — 변동형 약점은 여러 번 돌리면 건질 수 있지만, 일관형 약점은 모델을 바꾸기 전엔 안 사라집니다. 반복 업무는 안전하고, 단발 고난도는 위험하다는 이 글의 결론이 여기서 한 번 더 확인됩니다.
결론: 중소기업 온프레미스라면 충분히 AXy
정리하면 이렇습니다. SOTA급 고난도·규제 업무는 여전히 프런티어 모델의 몫이고, 그건 그들의 추론 서버 의존을 감수해야 합니다. 하지만 비용에 민감한 반복 업무라면, 그리고 중소기업 수준의 자체 온프레미스 환경이라면 — DeepSeek V4 Flash 정도면 충분히 AXy합니다.
어쨌든 '중국산 모델'이라는 사실보다 중요한 건, 그게 '중국 서버에서 추론'되고 있다는 점이니까요. 우리는 이 차이를 유념해서, 편견 없이 DeepSeek의 가능성과 상품성을 바라볼 필요가 있겠습니다.
자세한 벤치마크 결과는 → AXyBench 전체 결과 보기